MySQL - Using Barcodes As Primary Key
I was looking at a project recently that was using barcodes for the primary key on multiple tables.
This is fair enough, but it really bothered me that the primary key was a varchar type rather than one of the integer types.
For example, a barcode would be stored as something like
101111000110000101001110
I was frustrated with the fact that the barcode would not fit into the usigned BIGINT which has a max value of 18,446,744,073,709,551,615 and I started thinking that the solution was to use a reference table that assigned these string barcodes to auto incrementing ID, and I would then use this ID as a foreign key on my other tables.
However, that's pretty dumb. I failed to notice that the reason these varchars are so long is because they are binary. If one converts the barcodes from binary strings to their integer equivalents then the maximum possible value actually becomes manageable. Writing a function to convert to/from binary sounds like a pain, but PHP already has functions that do this for you! Check out bindec() and decbin().
Maximum Barcode Size
The maximum size of a GS1 barcode is apparently a sequence of 13 numbers (the EAN-13 format), according to this gs1.org page.
Thus, the maximum possible value would be 9,999,999,999,999 which easily fits within a BIGINT.
Benchmarking
Now all that's left to do is to find out if it is faster to take the overhead hit with converting to/from binary before running database queries, or if it's faster just to keep everything in binary strings. Thus, I created this benchmarking tool to do just that.
The tool generates two tables in a database which will hold a defined number of products. It populates both of those tables with the same product list, just one table is using the integer representations, whilst the other uses the binary string representations. I then time how long it takes to insert the data into each table, and how long it takes to read a defined number of random barcodes from each of the tables. To be fair, I made sure that the list of barcodes to be fetched was always the same for both tables.
Results
I got the following results when running the tool with 1,000 read queries per run. I was using my local computer as the database, running MySQL 5.7 on Ubuntu 18.04 (default configuration). My computer is a quad-core Intel Core i5-4670K CPU @ 3.40GHz with 16GB of RAM. It also uses a Crucial MX200 500GB SSD, so at least it's an SSD, but it's not something special like an optane drive.
Read Performance
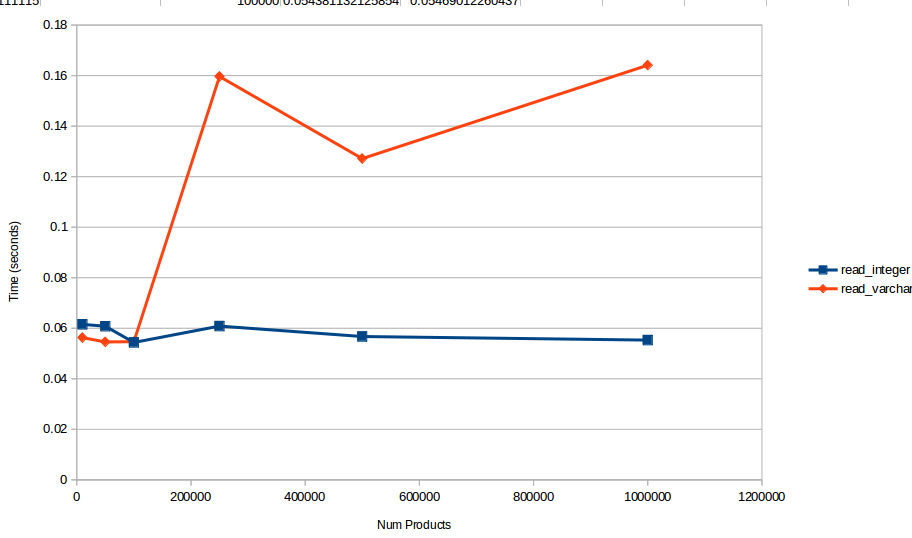
This graph shows how long it would take to read 1000 unique barcodes from each of the two table types. As you can see the time it takes to read from the BIGINT based table seems to hover around the same amount of time, but the varchar table proceeds to take longer to read the same number of products, as the table gets larger.
Write Performance
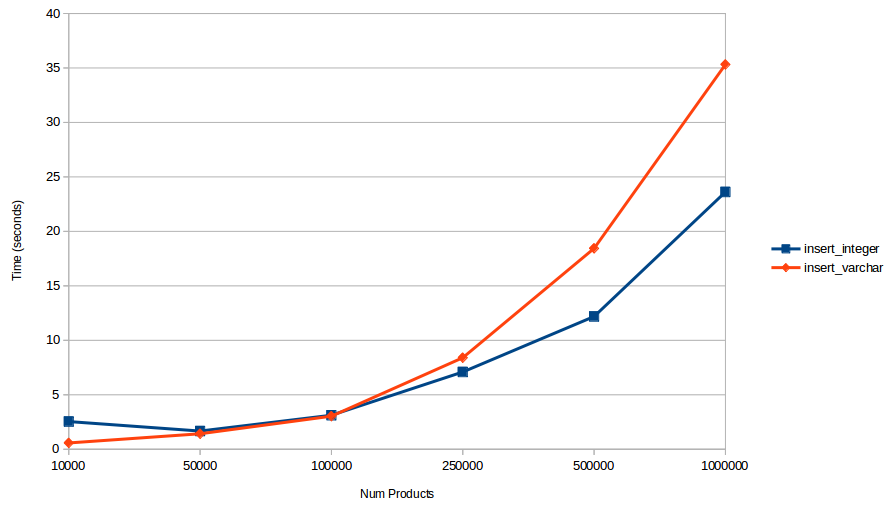
Writing to the tables always takes longer as the table gets larger. It was interesting to see that the varchar table is actually faster when really small, but gets slower at a faster rate, so using the BIGINT type really matters as the table grows.
Raw Results
If you want to see the raw numbers, they are below.
"num products", "insert_integer", "insert_varchar", "read_integer", "read_varchar"
"10,000", 2.5397818088531, 0.57751369476318, 0.061548948287964, 0.056288003921509
"50,000", 1.6711618900299, 1.4213862419128, 0.060801982879639, 0.054578065872192
"100,000", 3.121818780899, 3.0352013111115, 0.054381132125854, 0.05469012260437
"250,000", 7.0916981697083, 8.4011535644531, 0.060858011245728, 0.15963387489319
"500,000", 12.187259197235, 18.435462713242, 0.056723833084106, 0.12714099884033
"1,000,000", 23.616884231567, 35.314708471298, 0.055315017700195, 0.16410803794861
Taking It Further
I have an educated guess that using the BIGINT on queries that use table joins and nested queries would have a more noticeable impact, but this was the workload I wanted to test for now. Maybe I will take the tool further in future, or perhaps you can do this for me. I welcome people to point out if there are any mistakes in the source code. It was pretty rushed, so it is not my finest code, but it should be technically correct.
First published: 21st August 2019