GitLab - Reduce Memory Utilization
Background
I deployed a GitLab instance for a client a while ago, and since it was just a VPS on their own dedicated server, I decided to give allocate it more virtual CPUs than just the 2 I normally give them. This is because the vCPUs are "free", compared to if using traditional VPS hosting such as AWS or DigitalOcean where one has to pay more to get the additional CPU power.
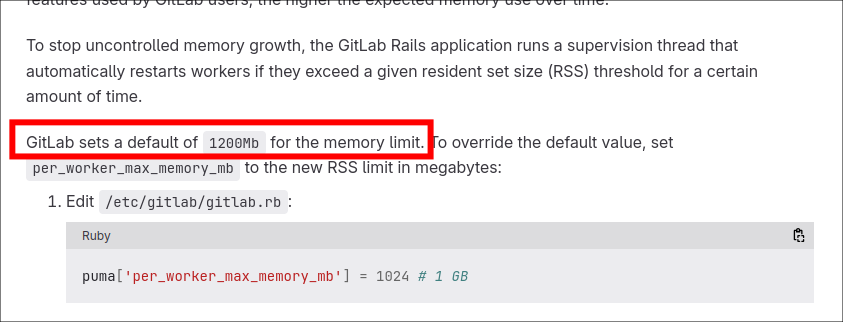
Zabbix eventually alerted me to the fact that it was running out of memory. After digging through forums and the config file, it looks like GitLab (by default) allocates a number of "Puma" processes dynamically based on the number of CPUs the instance has. These processes (by default) are given a limit of 1200Mb for their memory limit as shown from the docs below:
The Solution
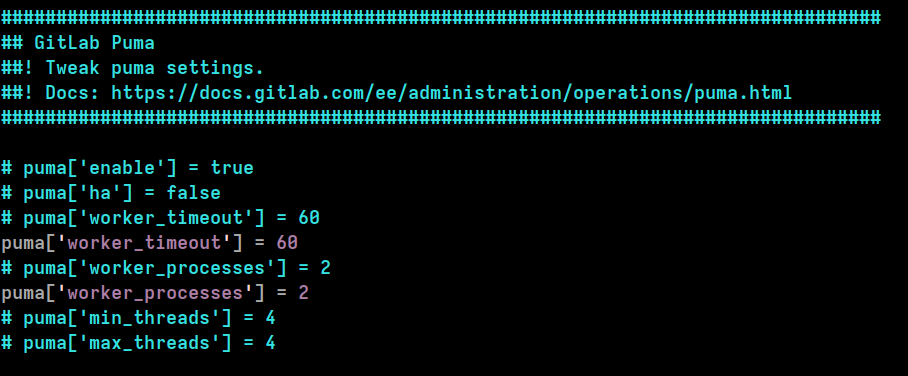
Thus, all I needed to do was edit the gitlab.rb configuration file to find the "GitLab Puma" section, and set the number of Puma processes to a fixed count of just 2:
puma['worker_processes'] = 2
.. as shown below:
... before then restarting the Docker container for the changes to take effect.
Graph Of Memory Impact
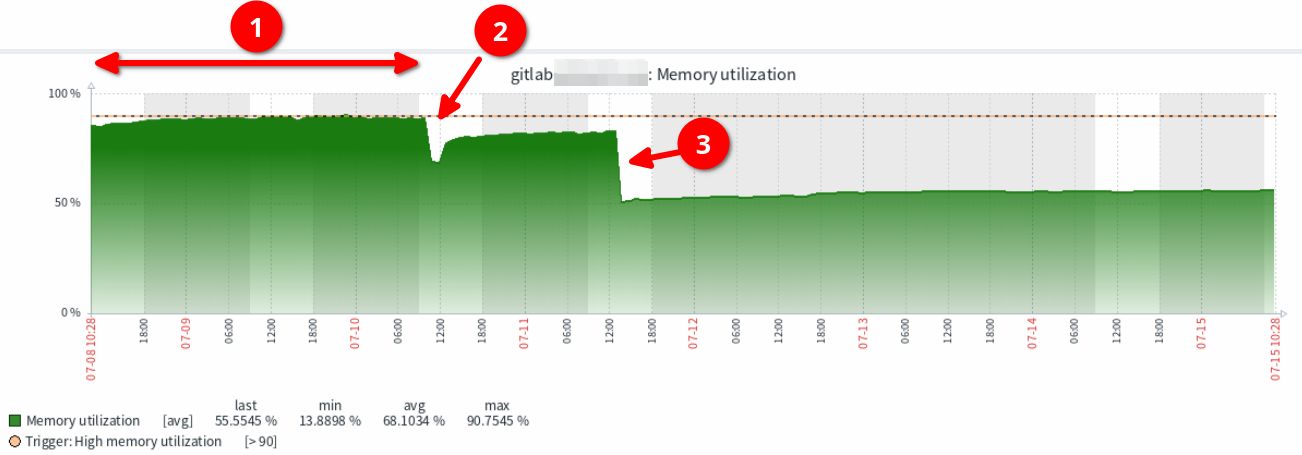
Below is a graph of memory utilization from Zabbix for the GitLab instance, which shows:
- The memory originally was quite large and grew over time to reach the 80% warning threshold.
- I restarted the GitLab Docker container with a different configuration change, that looked like it did not resolve the issue.
- I then changed the number of Puma processes to just 2 at point, which shows the massive impact on memory utilization.
What is Puma, and the potential drawbacks?
In case you're interested, apparently Puma is the default web server that took over from Unicorn. You can read more about GitLab's switch in the GitLab docs.
This does mean that by reducing the number of workers to just 2, we reduce the ability for GitLab to quickly handle lots of parallel requests. However, I am guessing that you are probably like me, with these instances only being used for private code repositories for a small team, and thus the ability to be able to handle lots of parallel requests isn't generally much of a need, compared to the need for reducing memory utilization. If you do need the performance, just be sure to scale your memory up with your core count.
References
First published: 19th July 2025