MySQL Performance When Using UUID For Primary Key
You may be concerned about the performance impact of switching from an auto-incrementing integer to a UUID. I decided to write some code to benchmark the batch insertion of millions of fake logs to see how much impact some various scenarios would have:
- Scenario 1 - using auto-incrementing unsigned integer.
- Scenario 2 - using UUID type 1 (time based).
- Scenario 3 - using UUID type 4 (random)
- Scenario 4 - using UUID type 4 (still random but manipulated to be sequential).
I published the code on Github if you would like to run the tests yourself, tweak them, or find any possible flaws with my logic. You can also download the results spreadsheet that has my test results and was used to generate the graphs in the body of this tutorial.
Test Results
Query Times
The chart below shows how long each of the insert queries (of 100,000 fake logs) took to make in seconds.
Please note that it just records the time that it took for the query to be sent off and completed, and not how long it took for my code to create the query as we are just measuring database performance here.

This chart shows the same results, but without UUID type 4 - random, so that you can more clearly see the performance difference between the other 3 scenarios.
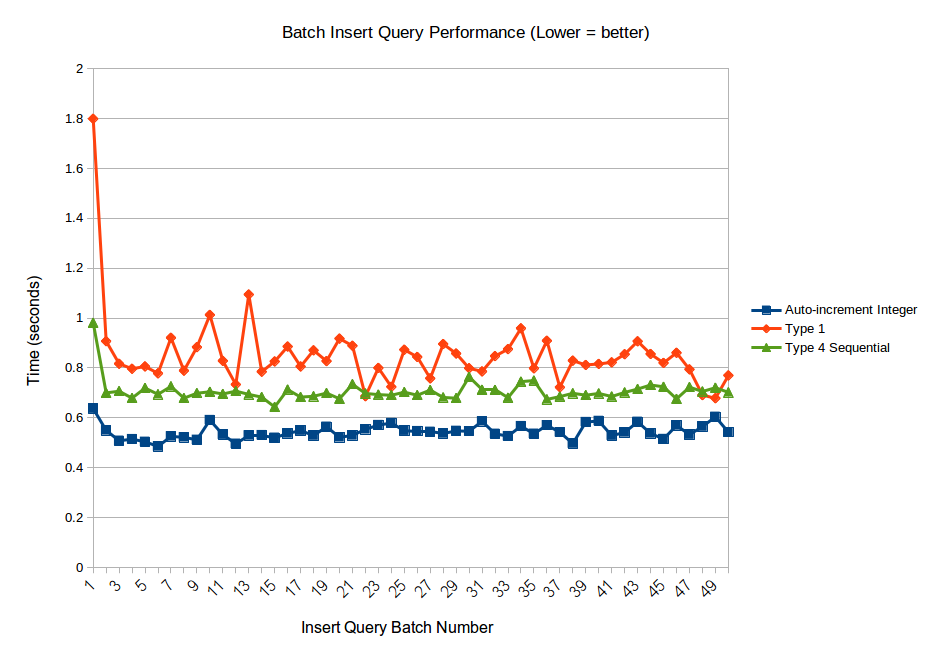
As you can see, using a "native" type 4 will kill performance if your table grows to a large size. This is because the records are not being just appended, but have to be inserted into the body of the table data each time. Using type 1 (time based and thus sequential) or sequential type 4 results in practically the same performance no matter what the table size, which is good to have.
Test Times
The chart below shows how long each of the tests took to run (inserting 5 million fake logs to an empty table). Not only does this account for long the queries took to run, but also how long it might have taken the software to generate the UUIDs necessary to create the query.

We would expect the "pure" type 4 UUID scenario to take longer than the others because the queries took so much longer to complete, however you can see that even the sequential type 4 takes noticeably longer than using type 1. This is because it takes noticeably longer for the code to generate these UUIDs which get fed into the queries. Watch your CPU utilization whilst the tests are running and you will see what I mean. Using type 1 UUIDs is still slower than using an auto-incrementing integer, but I feel that it is worth the cost. It took about a minute to insert 5 million fake logs which I consider an extreme workload.
Conclusion
Don't worry about the cost of switching to using UUIDs in your tables as performance can remain good, even as your table grows to millions of rows in size. You may wish to generate type 1 UUIDs if you need to produce massive numbers of UUIDs at a time (such as an archiving process), but a sequential UUID type 4 should be fine in most situations.
First published: 16th August 2018